
Maintenant que le blog est bien en place et qu’il est techniquement fonctionnel, je me suis dit qu’il serait intéressant de faire un petit point sur l’infrastructure que celui-ci utilise :) Le but n’est pas de vous donner un tutoriel pour chaque composant, beaucoup étant existant et très bons. Mais de vous expliquer mes choix et vous donner mon ressenti sur les solutions mises en place.
Infrastructure et choix
Les choix effectués sont très orientés nsa compliant cloud public, même si j’avoue préférer les solutions de cloud privé, notamment pour des raisons de confidentialité. Malgré cela 3 points m’ont orienté vers les solutions cloud public :
- Le rapport qualité / coût pour un hébergement de site statique. Les services utilisés (S3 et Cloudfront) permettent d’obtenir une disponibilité de près de 99,99%. Tout cela avec des performances franchement sympa, merci le CDN. Le tarif est relativement faible (entre 1 et 2 € par mois).
- Le cloud public offre pas mal de possibilités assez sympa que je souhaite tester pour augmenter mes compétences (notamment pour ma vie professionnelle).
- Le côté infra as a code très facile d’accès avec Terraform
Avant de commencer, voyons un petit schéma pour avoir une vue d’ensemble (c’est relativement simple) :
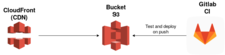
On y retrouve :
- Un bucket S3 qui va être utilisé pour stocker les sources du site générées par Hugo, mais j’y reviendrai plus tard.
- Une distribution Cloudfront, qui est un CDN (système de cache à l’échelle mondiale).
- Un Gitlab CI avec les runners qui vont biens pour versionner les sources et permettre de déployer automatiquement.
Le socle d’infrastructure (Terraform / AWS)
Amazon Web Service, plus communément appelé AWS est le service de public cloud d’Amazon. Il s’agit de l’un voire du service cloud public le plus connu. Il propose de nombreux services server-less managés. Ce qui permet de rapidement mettre en place des services sans se préoccuper de leurs installations, mises à jour et maintenance. C’est plutôt performant, pratique et uniquement facturé à la consommation. Après cela reste du cloud public, on n’a pas de vision sur ce qui se passe dans le datacenter et une fois chez eux on est assez dépendant de leurs services.
Mais ce qui est intéressant c’est que tout ça permet de créer et scaler à la volée tout ce qui est nécessaire dans une infrastructure, par exemple pour un site. C’est donc assez alléchant. En quelques minutes et quelques clics, il est donc possible de créer tout le nécessaire pour créer le blog, le stockage des sources (bucket S3), la distribution (CDN Cloudfront) et la génération de certificat. Mais bon on est pas encore tout à fait DevOps là, il reste pas mal d’actions manuelles qu’il serait très chronophage de reproduire.
Pour régler le problème, a émergé ce qu’on appel l’infra as a code, qui a pour but de provisionner son infrastructure avec du code. Pour cela plusieurs outils existent il est même possible de le faire à partir de logiciel d’industrialisation comme Saltstack ou encore Ansible. L’un des outils les plus connu et utilisé pour faire de la provision sur le cloud public reste Terraform. C’est un outil Open Source en Go édité par HasiCorp (comme Vault, Vagrant etc…). Il utilise des connecteurs lui permettant de s’adapter à divers providers, comme AWS, Azure, Vsphere ou encore OVH liste complète. Une fois celui-ci configuré, vous n’avez qu’à décrire les diverses ressources que vous souhaitez créer.
Voici un exemple très simple de code Terraform utilisé par le blog :
variable "bucket_site" {
default = "static-blog-tge"
}
resource "aws_s3_bucket" "static_blog" {
bucket = "${var.bucket_site}"
acl = "public-read"
cors_rule {
allowed_headers = ["*"]
allowed_methods = ["PUT","POST"]
allowed_origins = ["*"]
expose_headers = ["ETag"]
max_age_seconds = 3000
}
}
Dans cet extrait, on déclare une variable “bucket_site”, qui va contenir le nom du bucket. Ensuite on décalre une ressource, c’est à dire un objet AWS S3 dans notre cas en utilisant la variable créée précédemment.
Si vous souhaitez tester, le guide de démarrage du site officiel est assez clair Lien.
La génération du site statique (Hugo / Markdown)
Je voulais un blog qui me demanderait que peu d’entretien, pas avoir besoin de mettre à jour dans l’urgence régulièrement (même si cela aurait pu être automatisé), pas de problème de plugin, de performance, etc. Le plus simple pour ça étant de créer un blog statique. Par statique, comprenez qu’il s’agit uniquement de pages web déposés dans un buket accessible de l’extérieur. Le contenu est donc directement dans des pages HTML et n’est pas stocké dans une base de données.
Cela ne veut pas dire que nous allons écrire toutes les balises et les pages à la main (même si cela est possible). Il est en général conseillé d’utiliser un générateur de site statique. Globalement deux générateurs de site statiques sont actuellement très populaires, il s’agit de Jekyll et Hugo. J’ai choisi Hugo assez rapidement, même s’il ne supporte pas les plugins contrairement à son concurrent. Il est plus facile à prendre en main et il permet de générer des sites très performants rapidement (génération en quelques secondes).
Hugo s’utilise directement en CLI (un paquet est disponible dans les dépôts Debian). Il est ensuite assez simple de générer des articles qu’il faudra rédiger en Markdown. Si vous souhaitez voir comment ça fonctionne, voici un petit guide de base assez bien fait Lien
La CD (Gitlab CI)
Donc nous avons notre belle infra cloud qui est provisionnée par du code, c’est bien est plutôt sympa. Mais bon maintenant qu’on a tout ça et qu’on a tout mis sur git, ça serais encore plus sympa si à chaque push Gitlab testait les modifications et les déployait à notre place non ?
C’est là qu’arrive la partie que je trouve la plus fun, le déploiement continue (Continuous Delivery) ! On peut dire que c’est le but final de la majorité des DevOps, arriver à tout automatiser afin que le workflow s’enchaine automatiquement du test à la prod. Cela fait gagner beaucoup de temps, mais pour cela il est vital de passer assez de temps pour prévoir des tests automatiques robustes. C’est bien beau de déployer automatiquement, mais si cela crée des régressions ou bien des problèmes de sécurité c’est déjà moins sympa.
Pour mettre en place du déploiement continue sur ce site j’ai utilisé Gitlab CI. Le grand avantage est qu’il est très facile de passer d’un simple Gitlab à Gitlab CI, il suffit de configurer des “runners” qui vont exéctuer les étapes de la CD (que je fais fonctionner dans des Dockers) et ensuite de créer un fichier .gitlab-ci.yml dans le root du projet. C’est le fichier .gitlab-ci.yml qui va contenir tout votre enchaînement d’étapes, quoi faire (compiler, générer, tester, etc.), quand (automatiquement, si le job précédent est valide, manuellement, etc.) , où (sur quel runner).
Au final pour le site, j’ai décomposé ça en 2 projets git différents, donc 2 workflows de CD différents :
- L’infrastructure, qui contient tous les fichiers Terraform permettant de provisionner l’infrastructure. Ici ce n’est pas totalement automatisé dans la mesure où, il fait un différentiel pour voir les modifications apportées (Terraform plan) à l’infrastructure et ensuite il faut valider pour appliquer les modifications (Terraform apply).
- Les sources, qui lui contient les fichiers Markdown permettant de générer le site avec Hugo. La mise à jour est totalement automatique, si je push sur git des modifications automatiquement il va le déployer en suivant 3 étapes. Il génère tout d’abord le site avec le client Hugo. Il teste ensuite que les fichiers sont bien générés. Et si tout est bon il déploie les nouveaux fichiers sur le bucket S3 et invalide la cache pour mettre à jour le CDN.
Voici un exemple d’étape utilisée par ma CI :
apply:
stage: apply
environment:
name: production
script:
- terraform apply -input=false $PLAN
dependencies:
- plan
when: manual
Il s’agit de l’étape finale de la CI Terraform qui a pour but d’appliquer les modifications qui ont été faites sur Terraform. Vous pouvez reconnaître le format yaml, qui est le format utilisé par le fichier .gitlab-ci.yml. Ce morceau de code définit une étape qui s’appelle “apply” qui va effectuer un terraform apply sur l’environnement de production. Elle doit-être déclenchée à la main (cf when) et uniquement sur réussite de l’étape “plan”.
Si vous souhaitez en apprendre plus sur le fonctionnement de Gitlab et Gitlab Ci je vous conseille fortement la documentation officielle qui est très complète Lien.
Mon avis sur la stack
Voici donc la petite stack utilisée pour mon blog actuellement. Dans l’ensemble, je la trouve assez solide est assez agréable à maintenir notamment grâce à la CI / CD. Elle m’a aussi permis de mettre en pratique pas mal d’outils comme Terraform, Gitlab ou encore AWS. Le résultat obtenu correspond à ce que je recherchais, un blog simple, nécessitant peu de maintenance et performant à moindre coût. Je suis donc assez satisfait du résultat. J’ai notamment beaucoup apprécié l’écosystème offert par Gitlab que j’ai trouvé très fonctionnel et complet, il est dommage que cette expérience de Gitlab soit dégradée suite aux fuites mémoires régulières de celui-ci.
Après il me reste pas mal de choses à améliorer pour que cela soit encore plus obtimal. Notamment en ajoutant du monitoring, qui est pour l’instant inexistant. Je pense mettre en place du monitoring actif à terme, qui pourrait redéployer le site en cas d’erreur sur celui-ci. Le workflow CI du déploiement du site pourrait lui aussi être amélioré, en ajoutant notamment un test de perfomances et une étape de correction automatique d’orthographe.
Je pense que cela donne un bon exemple simple démontrant les possibilités qu’offres ces différentes technologies. Je vous tiendrai au courant des futures améliorations de ce site.