
J’héberge quotidiennement un ensemble de logiciels open source sur un serveur pour moi et mes proches : un Nextcloud, une instance GitLab (qui gère notamment la CI/CD du blog), un Pastebin et quelques autres outils. Le tout est hébergé via YunoHost.

Pourquoi YunoHost ? Ce n’est pas la solution la plus sexy techniquement, mais, elle est simple et efficace. Ma précédente stack était plus “intéressante”, mais à force de bricoler, j’avais dégradé les services. Pour des briques de base, ce n’était pas une bonne idée. De plus les sauvegardes se font facilement avec Restic sur du S3 dans mon cas.
Historiquement ma forge, qui est utilisée par deux personnes maximum, est sous Gitlab auto-hébergé. Ce qui en soi marche, mais reste très lourd à une si petite échelle. C’était d’ailleurs un choix voulu à une époque où j’étais formateur Gitlab et avoir une instance sous la main était très pratique. Sauf qu’aujourd’hui, je n’en ai plus spécialement besoin et Gitlab est lourd, au-delà de la lenteur, il consomme la majorité des ressources de mon serveur.
En clair, il était temps de passer à autre chose.
Note : Forgejo est un fork de Gitea suite à des changements de gouvernance (https://forgejo.org/compare-to-gitea/). Les deux sont encore quasi identiques actuellement. Dans cet article, je parlerai souvent de Gitea car j’ai commencé par lui, mais la logique reste identique. Merci à Philippe Charrière, Mi Dwo et ikarius de m’avoir fait découvrir ce fork.
Dans la théorie, tout est simple
On installe les deux, on utilise le script décrit dans la doc Doc officiel Gitea. On le laisse tourner, on check et c’est la bascule. On backup une dernière fois le Gitlab et on le supprime ensuite on passe le domaine sur notre nouvelle forge. Reste plus qu’à ajouter les runners et créer les workflows.
Globalement en une heure c’est réglé. Sauf que…
Dans la pratique, tout est compliqué
Dans la pratique, dès qu’on arrive au script on commence à avoir des soucis. J’essaye celui de la documentation et erreur, je regarde rapidement, je vois que le dépôt n’est plus actif depuis près d’une décennie. Bref, je n’ai pas envie de me lancer dans du debug de vieux code, qui a peu de chance d’être mergée. D’ailleurs le projet est le fork d’un fork, d’un autre fork.
Rapidement je tombe sur 2 autres projets, d’autres erreurs. Là 3 choix s’offrent à moi :
- Créer un nouveau projet, m’aider de l’IA et avoir un truc de base qui fonctionne. Un peu de temps, des tests, mais c’est une solution.
- Corriger un script existant, très ancien qu’il faudra sûrement update et dont la PR n’a que peu de chance d’être mergée. Avant de sûrement devenir à nouveau obsolète.
- Faire preuve d’imagination. Trouver une solution rapide pour mon besoin très minimaliste en peu de temps.
Bien que les 2 premiers points soient plus intéressants techniquement. J’avais envie de faire vite, mais surtout me poser la question : n’y a-t-il pas une solution plus simple à mettre en place et surtout à maintenir ?
Migrer les projets
Je me dis que le besoin est ultra basique, créer des projets d’un groupe Gitlab et les créer et synchroniser de l’autre côté (dans mon cas le groupe change).
Sauf que pour ce besoin simple, j’ai besoin à minima de gérer les fonctions suivantes :
- S’authentifier sur Gitlab / Gitea / Forgejo
- Fonction de base, lister les projets d’un groupe, créer des projets.
- Synchroniser un projet
- Gérer les erreurs et autres sur l’API.
En clair, beaucoup d’éléments assez basiques. C’est à ce moment que je me suis dit qu’il serait sympa d’avoir une sorte d’abstraction de code qui gère les interfaces vers les APIs. A ce moment je me dis, mais il y a une solution que tu utilises tous les jours : Terraform / OpenTofu / Pulumi.
On y pense pas dans ce type de cas, mais en réalité ces solutions reposent sur des providers qui assurent la liste de mes besoins et sont plus largement maintenus. On peut faire du code très simplifié. Je n’ai pas fait mon test avec Pulumi ayant mes habitudes avec Terraform / OpenTofu. Mais dans le cadre de migration plus conséquente ou professionnel, Pulumi se basant sur des langages plus complets que le HCL serait surement idéal.
Mon approche est simple : le code liste les projets du groupe source, puis crée les projets correspondants dans le groupe cible de la nouvelle instance. Le plus important est ici, le reste est disponible sur ce repo Github.
# Fetch all projects from either a GitLab group or user (personal namespace)
data "gitlab_group" "source_group" {
count = var.gitlab_group_id != "" ? 1 : 0
group_id = var.gitlab_group_id
}
data "gitlab_user" "source_user" {
count = var.gitlab_user_id != "" ? 1 : 0
user_id = var.gitlab_user_id
}
data "gitlab_projects" "group_projects" {
count = var.gitlab_group_id != "" ? 1 : 0
group_id = var.gitlab_group_id
archived = false
order_by = "name"
sort = "asc"
}
data "gitlab_projects" "user_projects" {
count = var.gitlab_user_id != "" ? 1 : 0
owned = true
archived = false
order_by = "name"
sort = "asc"
}
# Local variables for name sanitization
locals {
# Combine projects from either group or user source
all_projects = var.gitlab_group_id != "" ? data.gitlab_projects.group_projects[0].projects : data.gitlab_projects.user_projects[0].projects
# Sanitize repository names: replace spaces with dashes, lowercase, remove special chars
sanitized_projects = {
for project in local.all_projects :
lower(replace(replace(replace(project.name, " ", "-"), "_", "-"), "/[^a-zA-Z0-9.-]/", "-")) => project
}
}
# Output the list of projects for visibility
output "gitlab_projects" {
description = "List of GitLab projects from group or user"
value = {
for project in local.all_projects : project.name => {
id = project.id
name = project.name
description = project.description
http_url_to_repo = project.http_url_to_repo
ssh_url_to_repo = project.ssh_url_to_repo
path_with_namespace = project.path_with_namespace
}
}
}
# Create Gitea repository mirrors for each GitLab project
resource "gitea_repository" "gitlab_mirrors" {
for_each = local.sanitized_projects
username = var.gitea_username
name = each.key # Use sanitized name
description = each.value.description != "" ? "${each.value.description} (mirrored from ${each.value.name})" : "Mirror of ${each.value.path_with_namespace}"
mirror = true
migration_clone_addresse = each.value.http_url_to_repo
migration_service = "gitlab"
migration_service_auth_token = var.gitlab_token
lifecycle {
prevent_destroy = false
}
}
# Output the created Gitea repositories
output "gitea_mirrors" {
description = "List of created Gitea mirror repositories"
value = {
for name, repo in gitea_repository.gitlab_mirrors : name => {
name = repo.name
description = repo.description
clone_url = repo.html_url
}
}
}
Ce qui est top c’est qu’on peut créer directement le projet en mode miroir et donc récupérer en permanence les modifications de la première instance.
Le but est de donner mon exemple, mais on aurait pu migrer aussi les tickets de la même manière.
Important : Pensez à modifier les paramètres de Gitea/Forgejo > et ajouter votre domaine dans webhook_allowed_hosts.
Plus qu’à exécuter plusieurs fois ce code en fonction des groupes sources et cibles.
Vous pouvez une fois que vous avez basculé sur les nouveaux projets dans les paramètres passer le projet en projet standalone.
A partir de là j’ai directement basculé sur ce nouveau serveur, en supprimant Gitlab (avec une petite sauvegarde préalable) et en basculant le sous-domaine.
Mais ce n’est pas tout à fait terminé.
Migrer la CI/CD
J’ai migré en priorité la CI/CD de mon blog. Qui build des fichiers Hugo, vérifie que ça s’est bien généré et les push sur un bucket S3 avant d’invalider le cache.
Rien de très compliqué, la CI/CD est très similaire à Github. L’installation du runner se fait facilement en suivant la documentation officielle.
J’ai essayé de migrer de mon gitlab-ci vers les actions entièrement par l’IA, mais assez étonnamment les résultats étaient assez mauvais. Actions trop vieilles, erreur de dépendance, bref même en guidant, j’étais pas hyper satisfait. Je suis reparti sur un workflow simple qui marche sans soucis.
name: Gitea Actions - Déploiement blog
run-name: ${{ gitea.actor }} déploit une nouvelle version du site 🚀
on:
push:
branches:
- master
workflow_dispatch:
jobs:
Hugo-Deploy:
runs-on: main
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_DEFAULT_REGION: ${{ secrets.AWS_DEFAULT_REGION }}
steps:
- run: echo "🎉 La tâche a été automatiquement déclenchée par un événement ${{ gitea.event_name }}."
- name: ✅ Vérifier le code du dépôt
uses: actions/checkout@v4
with:
submodules: false
fetch-depth: 0
- run: echo "💡 Le dépôt ${{ gitea.repository }} a été cloné sur le runner."
- name: 🧰 Configurer Hugo
uses: peaceiris/actions-hugo@v3
with:
hugo-version: '0.111.3'
extended: true
- name: ⚙️Construire
run: hugo -d public
- name: Les fichiers suivants ont été générés
run: |
ls -la public
- name: 🌍 Publish to damyr.fr
uses: lbertenasco/s3-deploy@v1
with:
folder: public
bucket: ${{ secrets.AWS_S3_BUCKET }}
dist-id: ${{ secrets.DISTRIBUTION }}
invalidation: /*
- run: echo "🍏 L'état de cette tâche est ${{ job.status }}."
En simplifant le tout j’ai aussi gagné largement en terme de performance.
Au final
La migration n’était clairement pas complexe en soit, le scope était faible, pas de problématique de disponibilité ou autre. A la base je ne pensais même pas en faire un article, mais cette utilisation pour le moins originale de Terraform est intéressante.
Aujourd’hui quasi tous les outils ont des providers Terraform / OpenTofu, vos outils de ticketing, monitoring et autre. Cela permet d’étendre Terraform à des usages différents, d’économiser du temps et d’avoir une alternative au full code, qui comme je le disais nécessite souvent plus de maintenance.
Pour ce qui est de Forgejo, c’est efficient, l’ergonomie à la Github n’est pas dépaysante. Je n’ai pas eu de soucis majeurs, ça fait le job. Je n’étais pas au courant des changements de gouvernances de Gitea qui ont provoqué la création de Forgejo, je vous invite donc à considérer Forgejo plutôt que Gitea.
Pour ce qui est du sujet de départ c’est à dire la consommation de ressource, le défi est pleinement rempli. J’ai perdu 10% d’usage disque et j’ai gagné quasi 10Go de mémoire, et vu les prix actuels on peut dire que ça vaut de l’or.
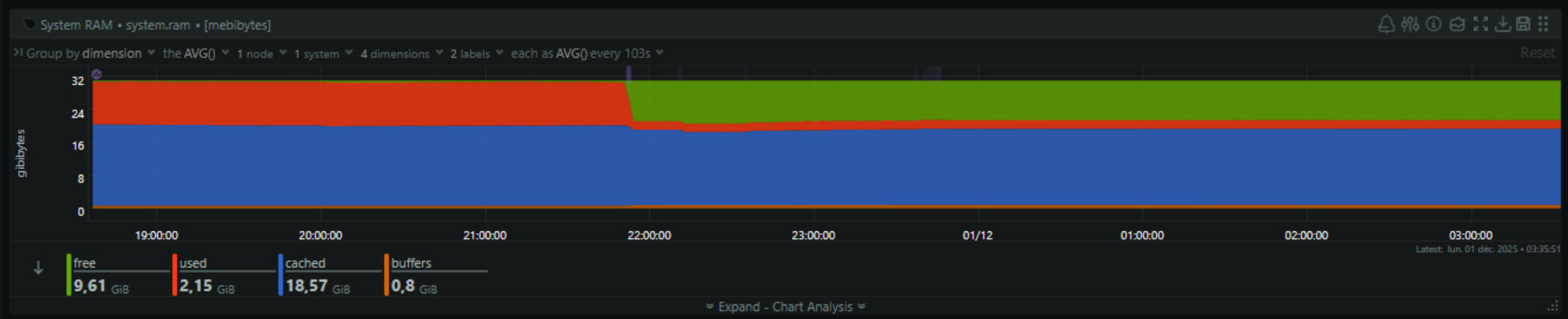
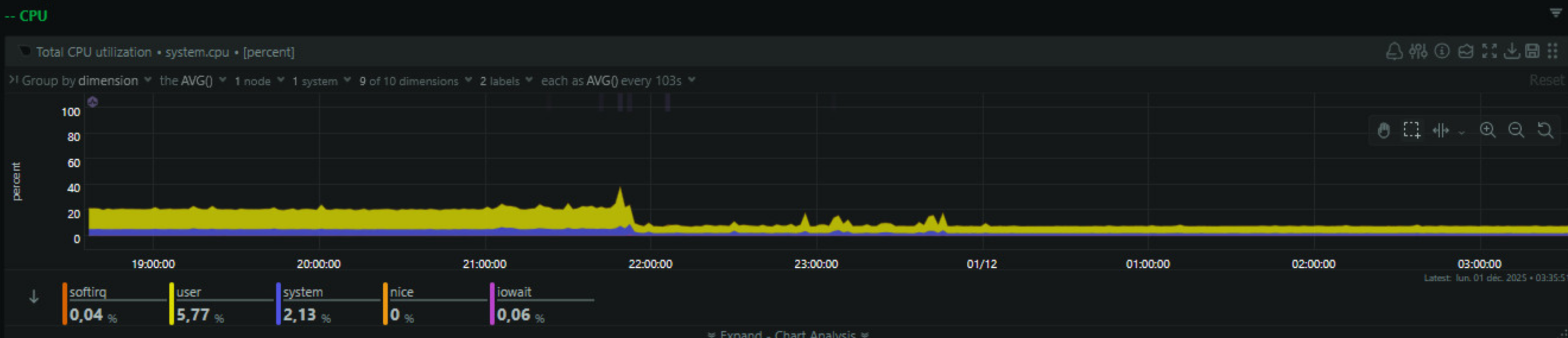
tl;dr : il faut parfois sortir des sentiers battus et utiliser les outils qu’on connaît de manière créative.
Photo de Massimo Botturi sur Unsplash